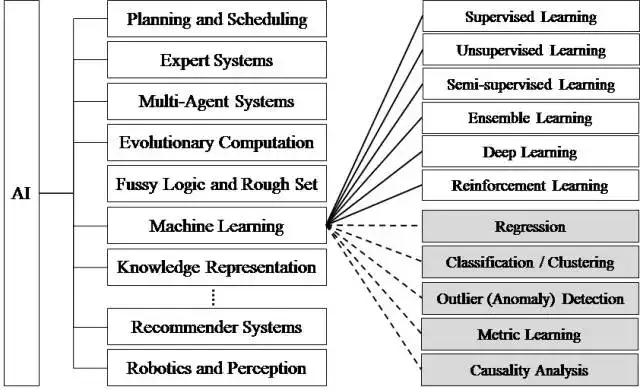
是的,Tensorflow 是一個機器學習的「框架」framework,框架是一個大家公認的規範,也就是在茫茫程式大海中,你可以有自己的習慣、有自己的開發方式、有自己的 API 接法等等。但是,若你與大家使用了共同的規範、共同的習慣,那所有人開發起來就會方便許多,你們可以共用某支程式,共用某些 API ,彼此間也能夠迅速成長。
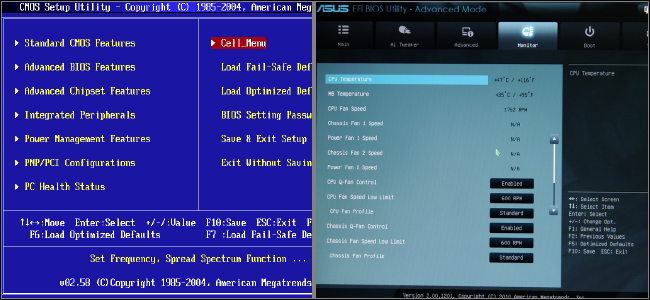
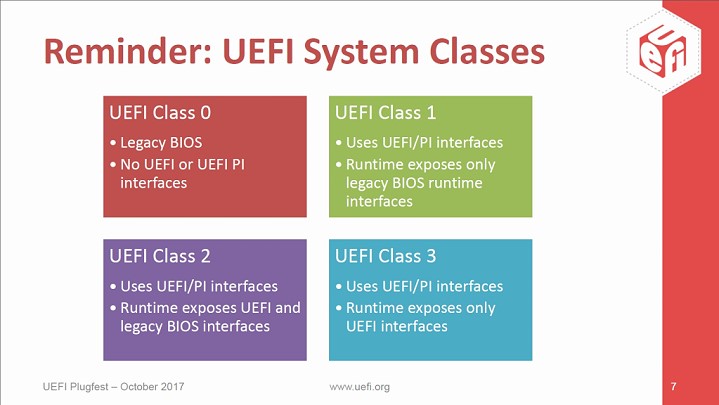
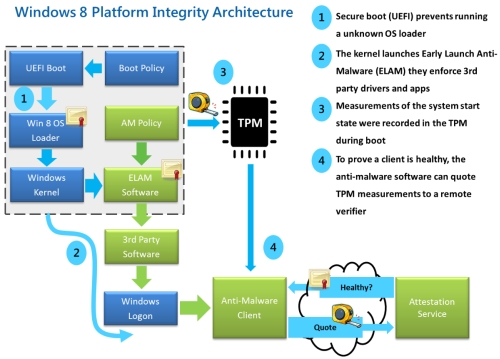
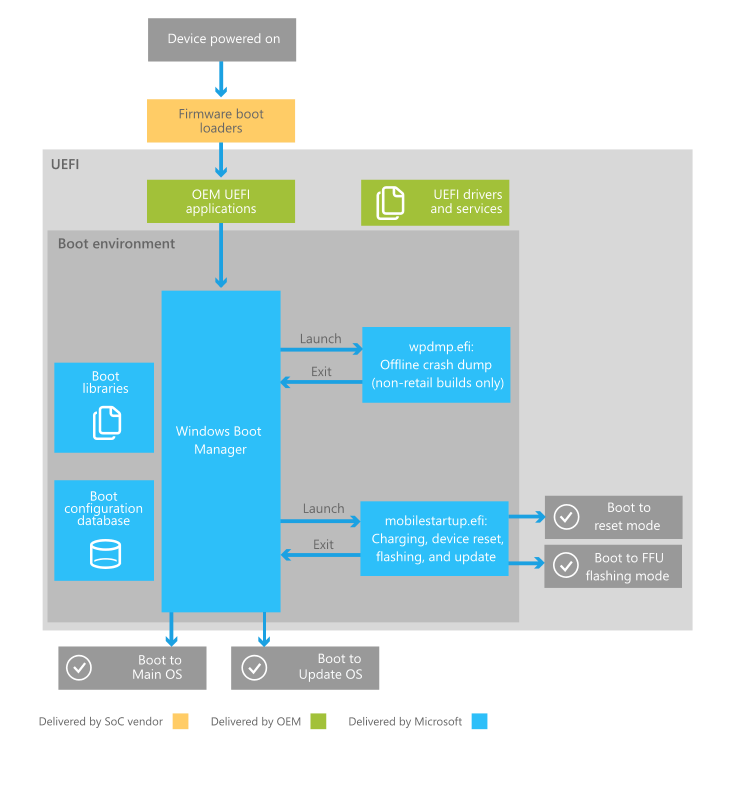
The UEFI 2.3.1 Errata C specification (or higher) defines a protocol known as secure boot, which can secure the boot process by preventing the loading of drivers or OS loaders that are not signed with an acceptable digital signature. The mechanical details of how precisely these drivers are to be signed are not specified.[49] When secure boot is enabled, it is initially placed in “setup” mode, which allows a public key known as the “platform key” (PK) to be written to the firmware. Once the key is written, secure boot enters “User” mode, where only drivers and loaders signed with the platform key can be loaded by the firmware. Additional “key exchange keys” (KEK) can be added to a database stored in memory to allow other certificates to be used, but they must still have a connection to the private portion of the platform key.[50] Secure boot can also be placed in “Custom” mode, where additional public keys can be added to the system that do not match the private key.[51] Secure boot is supported by Windows 8 and 8.1, Windows Server 2012, and 2012 R2, and Windows 10, VMware vSphere 6.5[52] and a number of Linux distributions including Fedora (since version 18), openSUSE (since version 12.3), RHEL (since RHEL 7), CentOS (since CentOS 7[53]) and Ubuntu (since version 12.04.2).[54] As of January 2017, FreeBSD support is in a planning stage.[55]
Science is NOT a battle, it is a collaboration. We all build on each other’s ideas. Science is an act of love, not war. Love for the beauty in the world that surrounds us and love to share and build something together. That makes science a highly satisfying activity, emotionally speaking!
import tensorflow as tf # Creates a graph. a = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[2, 3], name='a') b = tf.constant([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], shape=[3, 2], name='b') c = tf.matmul(a, b) # Creates a session with log_device_placement set to True. sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) # Runs the op. print(sess.run(c))
運行成功應該如圖,輸出運行之顯示卡序號
1
GPU 0
與運算結果
1 2
[[22. 28.] [49. 64.]]
:::
安裝 Visual Stduio Code
:::info Visual Studio Code(簡稱VS Code)是一個由微軟開發的,同時支援Windows、Linux和macOS作業系統且開放原始碼的文字編輯器。它支援偵錯,並內建了Git 版本控制功能,同時也具有開發環境功能,例如代碼補全(類似於 IntelliSense)、代碼片段、代碼重構等。該編輯器支援用戶自訂配置,例如改變主題顏色、鍵盤捷徑、編輯器屬性和其他參數,還支援擴充功能程式並在編輯器中內建了擴充功能程式管理的功能。
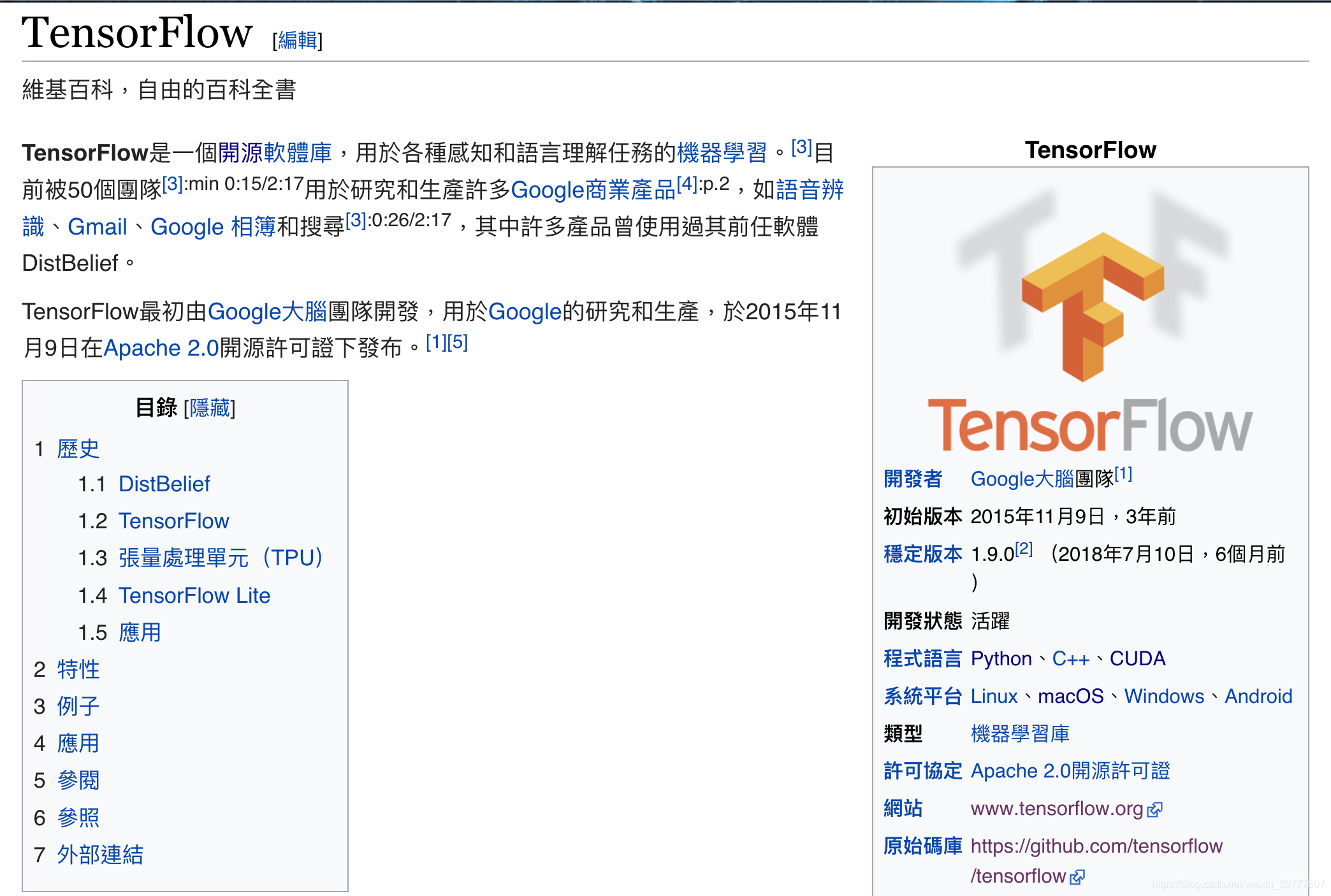
 這段告訴你,Tensorflow 既是一個機器學習的框架,更是一個實現機器學習算法的接口。
這段告訴你,Tensorflow 既是一個機器學習的框架,更是一個實現機器學習算法的接口。